Saving LLM token consumption
5h agoI recently discovered a way to save LLM token consumption, and its working really well. Previously i found a tweet post by @nayakayp that showed how to use rtk to save token consumption. I was curious to see if it would work with other LLMs, so i tried it with cursor.
rtk-ai use hooks, it invoke when the user type in a prompt via preToolUse hooks. we should know that each we call tools, each turn, the model output is added to the context window.
therefore, hooks pretty good to reduce bloating context window size. For example, when you wanted to force a model to use certain command or rules like “use pnpm instead of npm” we usually write it into AGENTS.md or CLAUDE.md or cursor rules but this is not always effective because the model may not follow the rules or it may not be aware of the rules but with hooks, we can easily achieve this.
Screenshots
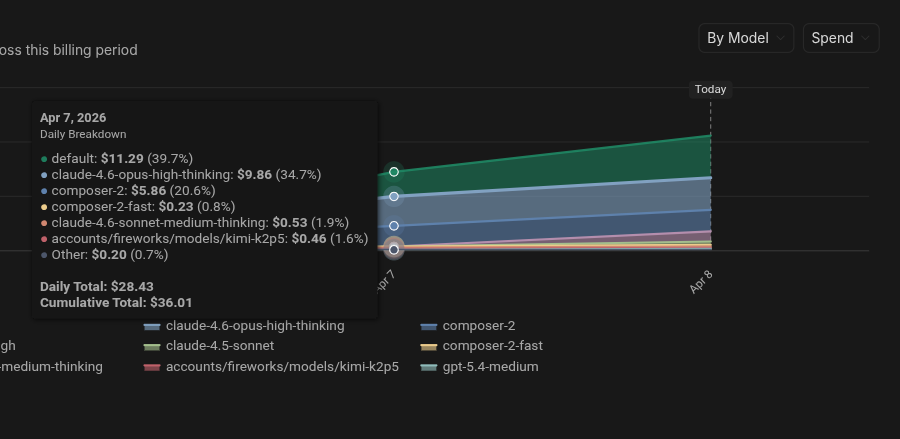 before
before
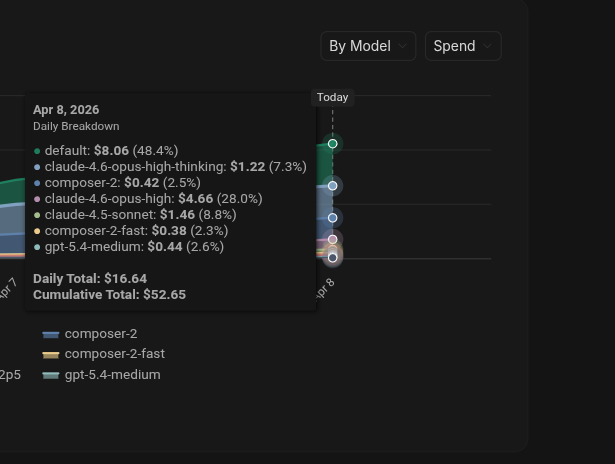 after
after
other way to reduce token consumption is to use smaller models when writing code and use larger models for planning, researching and thinking. like what i do, using Opus 4.6 for planning and brainstorming, and using composer 2 / auto to execute the plan.
Cursor use composer 2 fast as default to execute subagents, which is a great way to reduce token consumption, CMIIW.
for more information, you can check out the following links:
~ That’s it for now, happy ~vibe~ coding! ~